[AINews] Ways to use Anthropic's Tool Use GA • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
AI Discord Recap
AI Discord Communities Highlights
Modular (Mojo 🔥) Discord
LLM Finetuning Discussions
Building Internal Tool for Compliance
LLM Finetuning Communication Highlights
HuggingFace Discussions on Courses and Competitions
Perplexity AI General Discussions
Discord Server Conversations
Additional Chat API Discussion
Eleuther Discord Highlights
Interconnects: Nathan Lambert News
Resurrected Robotics Team and GPT-3.5 Discussion
AI Twitter Recap
The AI Twitter Recap mentions that the recaps are done by Claude 3 Opus, the best of 4 runs. The team is also working on clustering and flow engineering with Haiku. The section also covers AI Research and Development.
AI Discord Recap
- Model Performance Optimization and Benchmarking: The K2 model outperforms Llama 2 70B with less compute, NeurIPS hosts a model merging competition, and tailored positional embeddings boost Transformer arithmetic.
- Fine-Tuning and Prompt Engineering: Discussions include effective dataset merging during fine-tuning, fine-tuning techniques for legal draft systems and chatbots, and resolving training issues for text classification models.
- Open-Source AI Developments and Collaborations: Innovations like Milvus Lite for vector storage, MixMyAI platform for integrating multiple models, and LlamaIndex for retrieval systems.
- AI Community Innovations and Knowledge Sharing: Topics cover prompt consistency in Axolotl, challenges with Ghost XB Beta, and incorporating OpenAI and LangChain tools.
- Hardware Advancements and Compatibility Challenges: Discussions range from NVIDIA's new research chip efficiency to handling CUDA operations effectively. These conversations reflect the diverse range of topics discussed on the AI Discord channel.
AI Discord Communities Highlights
K2 Triumphs Over Llama 2
LLM360's K2 model outpaces Llama 2 70B with better performance and less computational effort. Researchers achieve 99% accuracy on 100-digit sums with tailored positional embeddings for transformers. NeurIPS Model Merging Competition offers an $8,000 prize. 150k+ datasets available for exploration with DuckDB. Reinforcement Learning and Computer Vision courses by Hugging Face.
Unsloth AI Guild Insights
Engineers discuss quantization challenges and NVIDIA's 4nm research chip. AI model fine-tuning strategies shared, including dataset merging. Troubleshooting tools for GPU selection and handling fine-tuning errors. Ghost XB Beta's multilingual support highlighted.
Perplexity AI Updates
Discussions on Tako widgets' geographic limitations and the end of Perplexity Pro trials. Users navigate editing quirks on Perplexity pages. Performance trade-offs in Perplexity Pro search noted. Exploration of new Perplexity features and models shared.
CUDA MODE Discussions
GPU innovations by NVIDIA and Meta generate excitement. FreeCodeCamp CUDA C/C++ course announced. Insights on practical challenges with scan algorithms and parallel computing. Strategies shared for model training and data optimization. Community celebrates milestones and enhances collaboration.
Stability.ai Dev Talk
Focus on online content privacy and eliminating contamination in Luxia models. Breakthroughs in communication with animals using AI. Puzzles over RLHF/DPO methods and preference learning. LLMs' real-time web content generation discussed.
Nous Research AI Updates
NeurIPS Model Merging competition details and $500K Coller Prize for animal communication AI. Surprises in RLHF/DPO methods challenge traditional algorithms. LLMs' influence on real-time web content highlighted. Google's AI Overviews upgrade aimed at enhancing user experience.
LlamaIndex Tech Chats
Merging Milvus Lite into AI applications for resource efficiency. Django-based web app template for RAG apps. Strategies for handling data transfer in retrieval systems. Different vector store query functionalities clarified. Troubleshooting SSL certificate verification for OpenAI setup.
Eleuther Community Insights
Contamination worries in Luxia 21.4b model and NeurIPS Model Merging competition. Advancements in CLIP text encoder methodology and PDE solver paradigm shifts acknowledged. AI engineers gear up for model selection and merging competition.
Modular (Mojo 🔥) Discord
The Modular (Mojo) Discord community is eagerly waiting for updates on a proposed package manager and discussing recent changes brought by the nightly Mojo compiler version. They are preparing for upcoming community meetings and are excited about the speed improvements demonstrated in a YouTube video. The community is also focusing on educational resources for compilers, proposing more efficient string builders, and discussing the use of iovec and writev for better memory management.
LLM Finetuning Discussions
LLM Finetuning (Hamel + Dan) Discord
- A member requested a session discussing Transformer architecture topics like vanilla transformer, RoPE, RMS Normalization, and more. Video resources were shared, emphasizing the need for interactive Q&A sessions.
- Google will allow free fine-tuning on Gemini Flash starting June 17th, viewed as a cost-effective opportunity. There was discussion on cost management for production-level systems using RAG LLMs and GPU time utilization.
- GGUF format was recommended for fine-tuning LLMs for compatibility with tools. Users shared experiences on document processing techniques like OCR and LiLT models.
- Users debated TensorFlow vs. PyTorch, highlighting ongoing framework preference debates in the community.
- Members discussed legal draft systems, fine-tuning LLMs for translating natural language into Cypher/GQL, and distinctions between instruct and chat LLM models.
- Topics included processing LinkedIn profiles for personalized introductions, utilizing Langsmith with OpenAI models, and connecting Langsmith to Langchain for AI integration.
- Link to valuable AI-coding humble bundle shared with skepticism on content quality, and links to learning resources and upcoming LLM-related book chapters provided.
- A member's inquiries on Langsmith-HIPAA compatibility and Langsmith's integration with other models were discussed. Members shared insights on gradient tricks like gradient checkpointing for optimization.
Building Internal Tool for Compliance
- A member is developing an internal tool that converts inputs like 'CloudTrail should have encryption at-rest enabled' into multiple files, including rego files compliant with a specific company schema. They are assessing whether the system's 66% accuracy is due to the retrieval method and considering fine-tuning the model for schema and code logic improvements.
- The tool currently retrieves entire documents for context, potentially overwhelming the model. Issues include code compilation errors, incomplete code, hallucinations, and incorrect logic, with considerations on whether fine-tuning could improve its adherence to schema.
- A member is refining a model to categorize Spanish text entities into persons, companies, or unions but faces poor performance during inference. They outline the multi-step instructions used for classification and seek advice on improving model accuracy.
- For multi-turn chat applications, there's a discussion on whether adhering to the official chat template is crucial when fine-tuning models to retain general utility without starting from scratch. A member assumes alignment is beneficial but looks for community confirmation.
LLM Finetuning Communication Highlights
LangChain Tools Discussion:
- Differentiation between LangChain, LangSmith, LangGraph, LangFlow, and LangServe.
- LangServe praised for API conversion.
- Interest in granular controls for LangServe.
- Challenges and learnings in GPU optimization.
Generative UI Hype:
- Discussion on GenUI for consumer AI understanding.
- Examples from CVP at W&B and Generative UI GitHub template.
Blog Post Sharing:
- User shared a blog post on LangChain and LangSmith experience.
- Encouraged further sharing for visibility.
Predibase Conversations:
- Free trial promotion for Predibase.
- Inquiry on selecting checkpoints after model fine-tuning.
Career Transition Stories:
- Experience sharing on transitioning from academia to data science.
- Tips on contracting as a lucrative option.
- Advice on facing job rejections and building a strong portfolio.
- Challenges of finding quality of life in tech roles.
Credit Form Deadline Discussions:
- Confusion on deadlines for credit forms submission.
- Clarification on last-minute submission flexibility.
- Reasons for delays in credit grants and solutions.
- Updates on Predibase registration and credit allocation timing.
Planned Events and Gatherings:
- Local gatherings announced in SF and NYC.
- Calls for meetups in DC and future events.
Community Engagement and Support:
- Various discussions on industry challenges and experiences.
- Encouragement for individuals transitioning to tech roles.
LLM Finetuning Concerns and Announcements:
- Queries on tool improvements, infrastructure controls, and system functionalities.
- Announcements regarding modal fixes and upcoming events.
HuggingFace Discussions on Courses and Competitions
HuggingFace ▷ #today-im-learning: Members of the community discussed queries about courses, including one on Unit 1's identity and information about courses like Reinforcement Learning and Computer Vision. They also shared a Community Computer Vision Course. Another section, #cool-finds, highlighted a NeurIPS model merging contest and a new paper on arithmetic with Transformers. Additionally, there was a discussion on LLMs, including the release of a new large language model called K2 that surpasses Llama 2 70B. The NLP section covered topics such as a model merging competition at NeurIPS and inquiries on sentence transformers. Lastly, in the general channel, there were conversations on finetuning strategies, new model creations like Llama-3 11.5B, and a possible new finetuning method called MoRA.
Perplexity AI General Discussions
The Perplexity AI channel featured various discussions on topics such as Tako Widget Queries, Pro Trials removal, editing page sections, slower Pro search, inquiries about Pro features and models. Users discussed limitations and enhancements within the Perplexity AI platform, offering feedback and seeking solutions to technical issues. The community engaged in conversations around efficient GPU programming, parallel processing, and improvements in CUDA technology. These discussions aimed to optimize workflows, enhance model performance, and share knowledge on advanced AI infrastructure development.
Discord Server Conversations
The section details various conversations on different Discord servers. In the CUDA Mode section, discussions revolve around Windows debugging for CUDA and compiler differences causing build errors. Triton difficulties and FP6 LLM discussions are acknowledged, with references to other channels for detailed talks. The Stability.ai section covers topics on privacy in online content, inconsistent results across different tools, combining models for improved outputs, training specific models, and resource recommendations for beginners. The LM Studio segment discusses GPU struggles with ROCm support, fixing unexpected endpoint errors, AVX2 requirement exclusion frustration, limitations faced in PDF and text-to-video applications, and localization and CPU instruction set issues. The OpenRouter section highlights enhancements in API performance, introduction of uptime charts, early preview of Category Rankings, release of a new Laravel package, API disruptions resolved, and a new model announcement featuring InternLM models. The OpenRouter App Showcase elaborates on MixMyAI.com offering pay-as-you-go AI services, emphasizing user privacy and showcasing a user-friendly UI. Chat conversations in the OpenRouter (Alex Atallah) channel include insight into the Latent Space podcast, OpenRouter Ruby library release, API issues, category rankings feedback, and a discussion on health check endpoints. The OpenAI section delves into discussions regarding new features and benefits for pro users, including higher rate limits and access to DALL-E, GPT creation, real-time voice, and video chat, along with suggestions for application use cases.
Additional Chat API Discussion
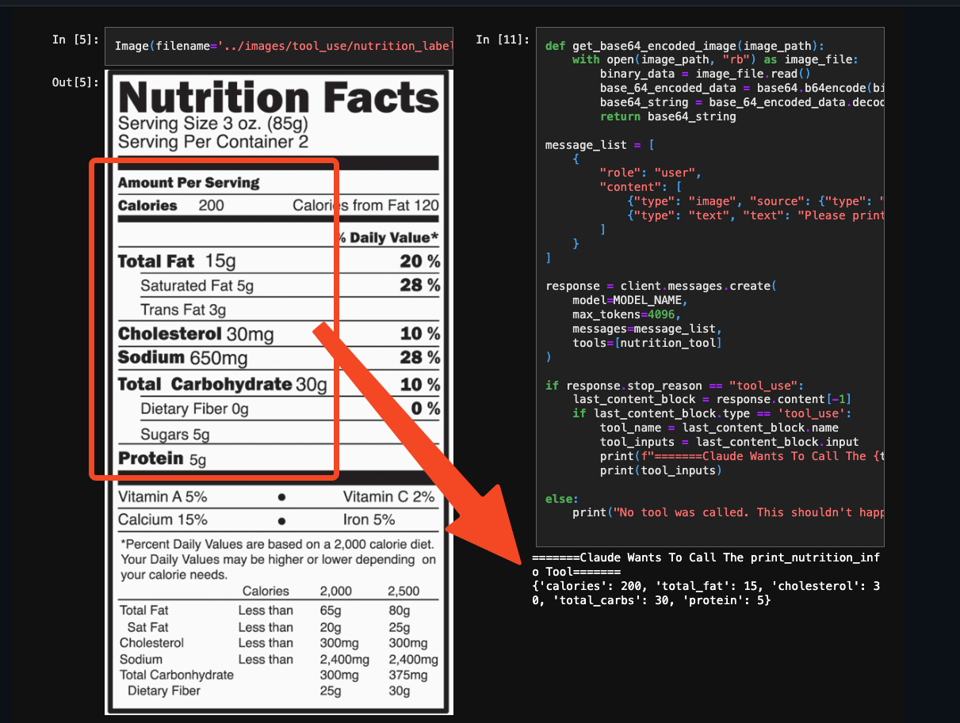
In this section, further discussions regarding the Chat API, model biases, and new AI features are highlighted. Members shared frustration over bias concerns with ChatGPT's responses and engaged in a conversation on model biases and training data. Additionally, comparisons between Anthropic's new 'tool use' feature and OpenAI's function calling were made, suggesting deeper integration with personal data. The excitement around new-gen video models like Sora and Veo was discussed, with skepticism raised about practical usability in current video AI technology.
Eleuther Discord Highlights
Transformers excel with MLPs:
- Transformers are praised for leveraging MLPs to achieve the best data dependence, especially in scaling.
Softmax attention debate:
- Discussions question the necessity of softmax weighted routing in data-dependent aggregation, with a member highlighting the importance of extensive trials.
Alternatives to softmax still resemble current methods:
- Arguments suggest that replacing softmax would not introduce a novel mechanism but rather form a 'function attention' maintaining a context-dependent T x T matrix. This implies that truly distinct methodologies might still have similarities to current attention mechanisms.
Interconnects: Nathan Lambert News
Google's New Compute Resources Ignite Interest: Mention of Google expanding its compute resources with a new cluster arriving. Court Verdict and its Implications: Users humorously discuss a high-profile court case, raising concerns about its impact on future political events.
Resurrected Robotics Team and GPT-3.5 Discussion
OpenAI has re-established its robotics team after abandoning previous efforts in 2020. The team, active for two months, is looking to hire research engineers. In another discussion, skepticism arises regarding the availability and accuracy of GPT-3.5 API for building chatbots. Clarifications are made about the timelines and versions of GPT-3.5 released. Users express confusion and frustration over deleted documentation related to GPT-3.5, raising concerns about the deletion of information. In another thread, members discuss recruitment for a project on physical intelligence, express interest in reinforcement learning and publishing, and reassure practical adaptability in research support involving robot usage.
FAQ
Q: What is the significance of the K2 model outperforming Llama 2 70B?
A: The K2 model outpaces Llama 2 70B with better performance and less computational effort. Researchers achieve 99% accuracy on 100-digit sums with tailored positional embeddings for transformers.
Q: What are some of the discussions around fine-tuning and prompt engineering?
A: Discussions include effective dataset merging during fine-tuning, fine-tuning techniques for legal draft systems and chatbots, and resolving training issues for text classification models.
Q: What are some of the open-source AI developments and collaborations mentioned?
A: Innovations like Milvus Lite for vector storage, MixMyAI platform for integrating multiple models, and LlamaIndex for retrieval systems are discussed.
Q: What topics are covered in the AI Community Innovations and Knowledge Sharing section?
A: Topics cover prompt consistency in Axolotl, challenges with Ghost XB Beta, and incorporating OpenAI and LangChain tools.
Q: What hardware advancements and compatibility challenges are discussed?
A: Discussions range from NVIDIA's new research chip efficiency to handling CUDA operations effectively.
Q: What are some of the insights shared in the Unsloth AI Guild discussions?
A: Engineers discuss quantization challenges, NVIDIA's 4nm research chip, AI model fine-tuning strategies, and troubleshooting tools for GPU selection.
Q: What updates are mentioned in the Perplexity AI section?
A: Discussions cover Tako widgets' geographic limitations, the end of Perplexity Pro trials, editing quirks, and performance trade-offs in Perplexity Pro search.
Q: What discussions are highlighted in the CUDA MODE section?
A: The discussions revolve around GPU innovations by NVIDIA and Meta, a FreeCodeCamp CUDA C/C++ course announcement, challenges with scan algorithms and parallel computing, and strategies for model training and data optimization.
Q: What is the focus of the Stability.ai Dev Talk?
A: The focus is on online content privacy, eliminating contamination in Luxia models, communication breakthroughs with animals using AI, and challenges and puzzles related to RLHF/DPO methods and preference learning.
Q: What updates are mentioned in the Nous Research AI section?
A: Updates cover the NeurIPS Model Merging competition details, a $500K Coller Prize for animal communication AI, surprises in RLHF/DPO methods, LLMs' influence on real-time web content, and Google's AI Overviews upgrade.
Q: What is discussed in the LlamaIndex Tech Chats?
A: Topics include merging Milvus Lite into AI applications, Django-based web app template for RAG apps, handling data transfer in retrieval systems, different vector store query functionalities, and troubleshooting SSL certificate verification for OpenAI setup.
Q: What insights are provided in the Eleuther Community Insights?
A: Insights include contamination worries in Luxia 21.4b model, advancements in CLIP text encoder methodology, and preparations for model selection and merging competitions.
Q: What is the focus of the LLM Finetuning (Hamel + Dan) Discord discussions?
A: Discussions cover transformer architecture topics, Google's free fine-tuning on Gemini Flash, cost management for production-level systems, TensorFlow vs. PyTorch debates, and topics like legal draft systems and categorizing Spanish text entities.
Q: What are some of the discussions highlighted in the LangChain Tools Discussion?
A: Discussions differentiate between LangChain, LangSmith, LangGraph, LangFlow, and LangServe, praising LangServe for API conversion, expressing interest in granular controls, and sharing challenges and learnings in GPU optimization.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!