[AINews] Google AI: Win some (Gemma, 1.5 Pro), Lose some (Image gen) • ButtondownTwitterTwitter
Chapters
Discord Summaries Highlights
Eleuther Discord Summary
LangChain AI Discord Summary
TheBloke - Characters Roleplay Stories
LM Studio Feedback
Nous Research AI Announcements
Eleuther ▷ #interpretability-general (38 messages🔥):
Diffusion Discussions
LlamaIndex & Mistral Discussions
Mistral Deployment
Discussions on Google's Gemma and AI Models
Discussions on Gemma Learning and Axolotl Configs
Torch, Groq's Architecture, and Optimization
Engagement and Updates
Highlights from AI Community Chats
Discord Summaries Highlights
TheBloke Discord Summary
-
Mixed Reception for Gemma Models: Users have differing opinions on Gemma models' performance, noting strengths and weaknesses in handling single prompts and multiturn responses.
-
Anticipation for AI Model Releases: Users discuss upcoming AI model releases and updates, such as the potential 'Llama 3' release in March and Google's AI development choices.
-
Roleplay and Character Complexity: Efforts to improve roleplay scenarios for chatbots are underway, with discussions on character consistency and varying GPU requirements for different models.
-
Dataset Editing and Model Training: Users face challenges in editing synthetic datasets and incorporating negative examples in training, exploring solutions like Gradio and effective classifiers.
-
Technical Conversations on Coding: Development of a chatbot script with multiple coding assistants, utilization of RAG techniques, Mistral finetuning, and backend infrastructure optimization for models are discussed. Preference for Zed over VSCode is mentioned, along with GPU suggestions for model optimization.
LM Studio Discord Summary
-
Dual GPUs and Power Requirements: Users caution about PSU requirements for dual GPU setups and note the importance of GPU speed matching in multi-GPU configurations.
-
Troubles with LM Studio 0.2.15 Beta: Users encounter issues with the beta version, such as problems with features and model output, leading to bug fixes and a re-release of Version 0.2.15.
-
Integration of Gemma Models: Gemma model support is added to LM Studio, with manual download options and recommended quant for easier integration.
-
AI Assistant Features and Troubleshooting: Users express interest in new LM Studio features, encounter display and RAM issues, and discuss troubleshooting potential Visual Studio Code and venv problems.
-
Microsoft's UFO Repository: A user shares Microsoft's UFO repository link, though context and relevance are not provided.
Nous Research AI Discord Summary
-
Context With ChatGPT: Experiments reveal ChatGPT's limitation to contexts by characters rather than tokens, sparking discussions on scaling language models to larger contexts and VRAM requirements.
-
AI-Driven Simulators and Self-Reflection: Users discuss AI-driven game simulations, OpenAI's Sora simulating Minecraft, and training non-expert models on microscopic images for artistic purposes.
-
Library Releases and Model Evaluations: New library releases like mlx-graphs optimized for Apple Silicon, Gemma 1.5 Pro's learning capabilities, and discussions on AI model evaluations without affiliations are highlighted.
Eleuther Discord Summary
Model Dual Capabilities Spark Interest:
Users are intrigued by diffusion models that can handle both prompt-guided image-to-image and text-to-image tasks, like Stable Diffusion. Google's release of Gemma, a family of open models, has also piqued interest, with Nvidia collaborating to optimize it for GPU usage.
License Wrestles and Governance Questions:
There's an ongoing discussion surrounding the licensing of models such as Google's Gemma, the potential for copyrighting models, and its implications for commercial use. Meanwhile, the governance of foundation models, including AGI, is drawing attention for policy development, like mandated risk disclosure standards.
Intelligence Benchmarks and Transformer Efficiency:
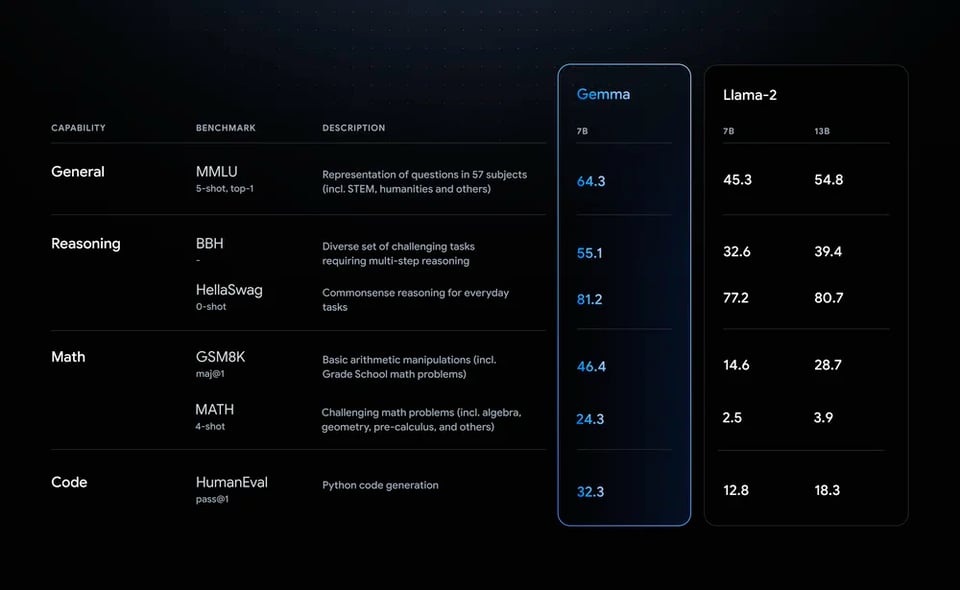
Debates heat up over the validity of current benchmarks, like MMLU and HellaSwag, for evaluating model intelligence. Users are also interested in finding the most information-efficient transformer models and comparing performance against MLPs and CNNs at various scales.
Uncovering Multilingual Model Mysteries:
There's curiosity over whether multilingual models, like Llama-2, are internally depending on English for tasks, with research approaches such as using a logit lens for insights being shared. Questions are also being asked about the potential for language-specific lens training.
Tweaking Code and Handling OOM:
In the realm of AI development, practitioners are tackling practical issues, such as resolving Out of Memory (OOM) errors during model evaluation and making tweaks to code for better model performance. Specifically, issues with running Gemma 7b in an evaluation harness and confusion regarding dropout implementation in ParallelMLP are points of discussion.
LangChain AI Discord Summary
TypeScript and LangChain: A Hidden Miss?
- @amur0501 questioned the efficacy of using LangChain with TypeScript, considering Python-specific features. The community remains divided on whether langchain.js matches its Python counterpart.
Function Crafting with Mistrial
- Using function calling on Open-Source LLMs (Mistral) has practical demonstrations by @kipkoech7, including local use examples and with Mistral's API. Check out the GitHub resource for more insights.
Vector Database Indexing Dilemma
- @m4hdyar sought strategies on index updates for vector databases post-code alterations. @vvm2264 suggested a code chunk-tagging system or a 1:1 mapping solution, yet no definitive strategy emerged.
NLP Resources Remain Outdated
- @nrs9044 sought recommendations for up-to-date NLP materials surpassing 2022's offerings. The latest libraries and advancements in the field remain insufficiently followed up.
AzureChatOpenAI Configuration Woes
- @smartge3k faced an error configuring AzureChatOpenAI within ConversationalRetrievalChain, resulting in a 'DeploymentNotFound' error. Community solutions for this issue are yet to be found.
Pondering a Pioneering PDF Parser
- @dejoma expressed interest in enhancing the existing PDFMinerPDFasHTMLLoader / BeautifulSoup parser with a week of dedicated work, seeking collaboration with like-minded individuals.
One-Man Media Machine
- @merkle highlighted how LangChain's langgraph agent setup can help transform solitary ideas into newsletters and tweets, citing a tweet from @michaeldaigler_ describing the process.
A Hint of an Enigmatic Endeavor
- @pk_penguin tantalized users with a potential new project or tool, inviting curiosity and private messages from those intrigued to explore the mysterious offering.
RAG Revisions via Reflection
- @pradeep1148 shared a YouTube tutorial on 'Corrective RAG using LangGraph,' featuring methods to enhance generative models. Another video on 'Self RAG using LangGraph' further supplements the discussion.
TheBloke - Characters Roleplay Stories
Miqu's Rush vs Goliath's Pace: Concerns raised about the pace of Miqu and its derivatives in scenes, with users sharing experiences and suggestions for adjusting prompts.### DPO Experiments for Roleplaying: Proposal to create DPO data for character roleplay, with interest from users and mention of existing models employing similar concepts.### Untruthful DPO: Detailed plan to create DPO pairs to train models to lie about specific topics, enhancing selective character responses.### Model Behaviours and Secrets: Discussion on LLMs keeping secrets and challenges in maintaining nuanced responses.### Resource Requirements for Miqu-70b Models: Varied discussions on model VRAM usage and memories of different sizes impacting user experiences.### AI Struggles in Character Consistency: User seeking help for maintaining consistent character role-play using a specific model, with suggestions and results shared.
LM Studio Feedback
LM Studio Feedback
- RAM Discrepancy Issue Raised: User
@darkness8327mentioned an issue with RAM display in the software they are using. - Assistant Creation Feature Request:
@urchiginquired about integrating assistant creation in LM Studio similar to Hugging Face. - Instructions for Local LLM Installation Sought:
@maaxportsought guidance on installing a local LLM with AutoGPT on a rented server. - Update on Client Version Confusion:
@msz_mgshighlighted an issue with client version 0.2.14 incorrectly indicating as the latest, and@heyitsyorkieadvised manual update installation. - Gemma Model Troubleshooting:
@richardchinnisreported Gemma model issues but later intended to try a different model based on discussions elsewhere.
Links mentioned
- HuggingChat - Assistants: Browse HuggingChat assistants made by the community.
Nous Research AI Announcements
- Introducing Nous Hermes 2:@teknium announced the release of Nous Hermes 2 - Mistral 7B - DPO, an in-house RLHF'ed model improving scores on benchmarks like AGIEval, BigBench Reasoning Test, GPT4All suite, and TruthfulQA. The model is available on HuggingFace.
- Get Your GGUFs!: Pre-made GGUFs (gradient-guided unfreeze) of all sizes for Nous Hermes 2 are available for download at their HuggingFace repository.
- Big thanks to FluidStack: @teknium expressed gratitude to the compute sponsor FluidStack and their representative, along with shout-outs to contributors to the Hermes project and the open source datasets.
- Together hosts Nous Hermes 2: @teknium informed that Together.xyz has listed the new Nous Hermes 2 model on their API, available on the Togetherxyz API Playground. Thanks were extended to @1081613043655528489.
Eleuther ▷ #interpretability-general (38 messages🔥):
Exploring LLM's Internal English Dependency:
- @butanium shared a Twitter link suggesting that multilingual models like Llama-2 might internally depend on English, as demonstrated by logitlens favoring English tokens for French to Chinese translations.
Tuned vs Logit Lens for Model Insights:
- @butanium highlighted a research approach using logit lens to determine if Llama-2 accesses English internal states during non-English tasks; the tuned lens would obscure such insights as it maps internal states to non-English predictions.
Stella Deck Comparison Announced:
- @butanium reacted to a Twitter post by @BlancheMinerva which seemingly depicted Stella already set up to perform related experiments.
Replicating Research with Available Code:
- @mrgonao is willing to run experiments to replicate study findings using provided code, but identified missing components including a tuned lens for the 70b model and a separate repetition task notebook.
Seeking Data for Language-Specific Lens Training:
- Discussion between @stellaathena and @mrgonao about the possibility of training a lens specifically for Chinese and considering the use of datasets like the Chinese shard of mC4 on Hugging Face.
Diffusion Discussions
- Seeking Damage Detection in Art: User @div3440 is working on a project using stable diffusion model activations to detect damage in paintings. They've tried using various techniques but face challenges due to language specificity and inconsistency in damage prominence.
- Alternative Damage Detection Suggestions: User @chad_in_the_house suggests considering GANs or synthetic data generation for training classifiers. They discuss zero-shot approaches to identify damage without additional data.
- Challenges in Dataset Curation: Collecting data involved manual selection of damaged artworks from Wikipedia and museum collections, highlighting the difficulty due to lack of specific metadata regarding damage.
- AI Generative Models for LSTM Images: User @lucas_selva seeks services for generating images of LSTM neural networks or free templates without copyright, although no clear solution is presented in the discussion.
- Diffusion Model Internals Enlighten: User @mr.osophy seeks to understand the U-Net architecture in diffusion models, particularly its usage of an integer parameter 't' affecting processing, learning about its relation to Fourier transforms for timestep embeddings.
LlamaIndex & Mistral Discussions
This section discusses various topics related to LlamaIndex and Mistral AI models, including announcements, inquiries, challenges, and potential solutions. Users engage in conversations about data quality benchmarks for large language models (LLMs), implementing multi-label classification with T5, error resolution with TensorFlow, and custom embeddings for biomedical terms. Additionally, discussions cover topics such as detecting damage in art using stable diffusion model activations, extracting latent tensors from prompts, and the launch of new services like LlamaCloud and LlamaParse. The section also delves into Mistral AI's speed, brevity preferences, censorship concerns, potential model releases, and open-source status, along with inquiries about function calling capabilities and chat interface construction using Mistral AI.
Mistral Deployment
This section covers various discussions on Mistral deployment in the Mistral Discord channel. Users inquire about running Mistral models with TensorRT, estimating hosting costs on AWS, API availability for Mistral-Next, and seeking guidance on efficiently deploying Mistral models for production purposes. Discussions include insights on model performance, quantization benefits, and the art of crafting effective prompts for desirable model responses. Links mentioned offer resources for deploying Mistral models using vLLM through a Docker image or Python package.
Discussions on Google's Gemma and AI Models
This section covers various discussions surrounding Google's Gemma models and other AI-related topics. Users share insights on issues such as the processing of symbols by GPT-4-1106, the importance of explicit instructions for AI behavior, comparisons between different AI models, and using AI as an assistant programmer. Additionally, updates on upcoming AI seminars, interest in new Karpathy lectures, and discussions on AI breakthroughs are highlighted. The section also delves into the integration of AI capabilities into products, the impact of Flash Attention on fine-tuning models, and the unveiling of Gemma with instruction-tuned variants. Furthermore, details on Gemma's open access and reposting are discussed, along with links to further resources mentioned in the conversations.
Discussions on Gemma Learning and Axolotl Configs
Updated Axolotl Config Shared for Gemma Training:
- @stoicbatman provided an updated Gemma config for compatibility with Axolotl.
- Discussions arose on Gemma Learning Rate and Weight Decay Values, with mentions of inconsistencies in Google's documentation regarding these values, referencing Colab notebook and Hugging Face blog post.
Torch, Groq's Architecture, and Optimization
This section discusses various topics related to Torch, Groq's architecture, and optimization efforts. It includes inquiries about broadcasting semantics in Torch and debugging issues with the GeForce 40 series. Additionally, there are mentions of PyTorch optimization details, the acceleration and optimization of generative AI models, and the use of different kernels for optimization processes. Links to related content such as PyTorch documentation, debugging tips, and relevant GitHub repositories are also provided.
Engagement and Updates
- Engagement with External Resources: Users shared a GitHub issue leading to another implementation of ring-flash attention and updates were given on learning experiences. Links to Google Colaboratory notebooks and GitHub repositories were shared.
- Learning and Progress Updates: Users shared their experiences with the project, contemplating learning cutlass primitives and delving into p2p overlap.
Highlights from AI Community Chats
In the recent discussions within the AI community, various topics were covered:
- Recognition and gratitude expressed by @swyxio.
- Call for the inclusion of grassroots contributors by @tokenbender.
- Inquiries about a token in the group by @scopexbt.
- Introduction and insights on Google's Gemini Pro 1.5 by @derekpwillis and @simonw.
- Technical issues and appreciation for directory names in the Datasette - LLM chats.
- Enthusiasm for Groq LPU's speed and coordination for weekend plans in the AI Engineer Foundation chat.
- Upcoming events and discussions on Gemini 1.5 and Semantic Knowledge in Audio in the AI Engineer Foundation events.
FAQ
Q: What are some of the challenges faced by users when it comes to gemma models' performance?
A: Users have differing opinions on Gemma models' performance, noting strengths and weaknesses in handling single prompts and multiturn responses.
Q: What AI model releases and updates are being discussed by users in the essay?
A: Users discuss upcoming AI model releases and updates, such as the potential 'Llama 3' release in March and Google's AI development choices.
Q: What are the key topics being discussed in the context of roleplay and character complexity for chatbots?
A: Efforts to improve roleplay scenarios for chatbots are underway, with discussions on character consistency and varying GPU requirements for different models.
Q: What are the challenges users face in dataset editing and model training according to the essai?
A: Users face challenges in editing synthetic datasets and incorporating negative examples in training, exploring solutions like Gradio and effective classifiers.
Q: What technical conversations on coding are being discussed in the context of chatbot script development?
A: Development of a chatbot script with multiple coding assistants, utilization of RAG techniques, Mistral finetuning, and backend infrastructure optimization for models are discussed.
Q: What concerns do users have regarding licensing of AI models and governance questions?
A: There's an ongoing discussion surrounding the licensing of models such as Google's Gemma, the potential for copyrighting models, and its implications for commercial use. Meanwhile, the governance of foundation models, including AGI, is drawing attention for policy development.
Q: What debates are happening regarding intelligence benchmarks and transformer efficiency?
A: Debates heat up over the validity of current benchmarks, like MMLU and HellaSwag, for evaluating model intelligence. Users are also interested in finding the most information-efficient transformer models and comparing performance against MLPs and CNNs at various scales.
Q: What is the curiosity around multilingual models and language-specific lens training?
A: Curiosity exists over whether multilingual models, like Llama-2, are internally depending on English for tasks, with research approaches such as using a logit lens for insights being shared. Questions are also being asked about the potential for language-specific lens training.
Q: What are the practical issues being tackled in AI development according to the essai?
A: In the realm of AI development, practitioners are tackling practical issues, such as resolving Out of Memory (OOM) errors during model evaluation and making tweaks to code for better model performance.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!