[AINews] Claude 3 is officially America's Next Top Model • ButtondownTwitterTwitter
Chapters
High-Level Discord Summaries
OpenRouter (Alex Atallah) Discord
CUDA MODE Discord
AI Shared Repository and Installation Challenges
AI Research Discussions
OpenInterpreter Community Discussions
Immediate Storage in RAM Request
LM Studio Discussions
Investigating the Limits of N-Gram Models
LangChain AI Tutorials
AI and Sales Agents, Voice Chat with Deepgram & Mistral AI, and CUDA Discussions
Using Prompt Formats for Multilingual Fine-Tuning
High-Level Discord Summaries
High-Level Discord Summaries
This section provides insights into various Discord communities discussing AI-related topics. Discussions range from SD3 release impacts, advancements in AI-assisted video creation, face swapping algorithms like Reactor, and the debate on the future of open-source AI. Additionally, hardware considerations for upscaling, performance comparisons between models, and challenges in fine-tuning AI are highlighted. Each Discord community delves into unique aspects such as the ethical implications of developing ASI, integration issues with GPT Store, and the importance of precise prompts for LLMs. Overall, these summaries offer a glimpse into the diverse discussions shaping the AI landscape.
OpenRouter (Alex Atallah) Discord
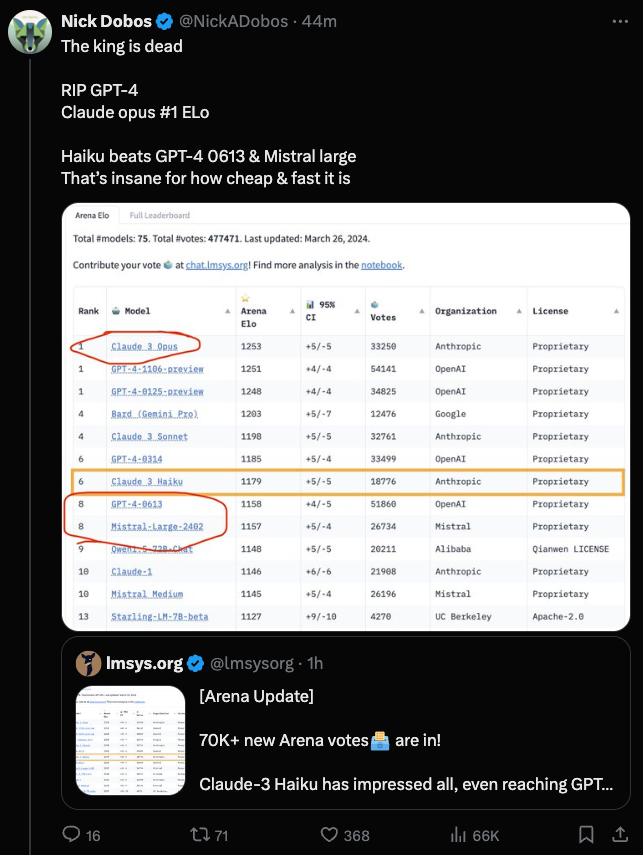
Users across the OpenRouter (Alex Atallah) Discord channel engaged in various discussions and shared insights. Topics included testing Opus on OpenRouter and observing a decline in guideline adherence, resolving 403 errors when accessing Anthropic models via OpenRouter, clarification on the use of sillytavern for chat completion, and a comparison between GPT-4 and Claude-3 in coding tasks. Additionally, there were discussions about payment fees, model weight storage strategies, and issues with model interactions and compatibility. The community also explored AI creativity, hackathon successes, and upcoming webinars. Finally, the community delved into the integration of the Mistral model with various technologies and discussed the impact of model fine-tuning on performance.
CUDA MODE Discord
- When I/O Becomes a Bottleneck: Using Rapids and pandas for data operations can be substantially IO-bound, especially when the data transfer speed over SSD IO bandwidth sets the bounds, making prefetching ineffective in enhancing performance since compute is not the limiting factor.
- Flash Forward with Caution: Deprecated workarounds in Tri Das's implementation of flash attention for Triton have sparked discussions on potential race conditions, with suggestions to remove obsolete workarounds and comparisons against slower PyTorch implementations for reliability validation.
- Enthusiasm for Enhancing Kernels: Community interest in performance kernels is evident, with API synergy opportunities highlighted as well as ongoing advancements in custom quant kernels for AdamW8bit. The community also shows interest in showcasing standout CUDA kernels in a Thunder tutorial.
- Windows Bindings Bind-up Resolved: A technical hiccup involving _addcarry_u64 was addressed by using a 64-bit Developer Prompt on Windows for binding C++ code to PyTorch, resolving prior issues encountered in a 32-bit environment.
- Sparsity Spectacular: Jesse Cai's recent Lecture 11: Sparsity on YouTube was well-received, with participants requesting access to the accompanying slides to deepen their understanding of sparsity in models.
- Ring the Bell for Attention Improvements: Updates from the ring-attention channel detail productive strides with the Axolotl Project on WandB, showcasing better loss metrics using adamw_torch and FSDP with a 16k context along with shared resources for addressing FSDP challenges, including a PyTorch tutorial and insights on loss instabilities from GitHub issues.
AI Shared Repository and Installation Challenges
Interesting
Users expressed intrigue about the shared repository on transformer heads.
Links mentioned:
Unsloth AI (Daniel Han) - Help
- Users discussed confusion over changing Unsloth's quantization bits.
- Special formatting using "\n\n" was noted.
- Installation challenges with Unsloth included using 'pip' and 'conda' with errors related to llama.cpp GGUF installation.
- Tips for managing VRAM usage and batch size during fine-tuning were provided.
- Users were advised to use Trainer instead of SFTTrainer and suggested custom callbacks to record F1 scores during training.
Links mentioned:
- Google Colaboratory
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++
- GitHub - unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning
Masher AI Model Unveiled
- A member showcased the Masher AI v6-7B model on Hugging Face.
- The use of Mistral 7B ChatML notebook was mentioned.
- Model performance evaluation was done using the OpenLLM Leaderboard.
Link mentioned:
ORPO Step Upgrades Mistral-7B
- Implementation on Mistral-7B-v0.2 base model yielded a high first turn score on the Mt-bench.
- AI talent wars with Meta facing challenges in retaining AI researchers were discussed.
- Strategies were shared on expanding LLM vocabulary and translating Japanese manga.
- Users expressed enthusiasm for fine-tuning models for specific languages.
Links mentioned:
- yanolja/EEVE-Korean-10.8B-v1.0 - Hugging Face
- Reddit - Dive into anything
- Open Source AI is AI we can Trust — with Soumith Chintala of Meta AI
Introducing Creative Potential of Sora
- OpenAI shared insights on their collaboration with artists and filmmakers using Sora.
- Artists embraced Sora for both realistic and surreal creations.
Link mentioned:
AI Research Discussions
World Simulation Amazement
- Participants expressed astonishment at the World Simulator project, with comparisons made to a less comprehensive evolution simulation attempted previously by a member, adding to the marvel at the World Simulator's scope.
BBS for Worldsim Suggested
- The suggestion to add a Bulletin Board System (BBS) to the world simulator was made so that papers could be permanently uploaded and accessed, potentially via CLI commands.
Discussion on Compute Efficiency and LLMs
- Dialogue unfolded around whether LLMs could reason in a more compute-efficient language, linked to context-sensitive grammar and 'memetic encoding,' which might allow single glyphs to encode more information than traditional tokens.
GPT-5 Architecture Speculation
- References to GPT-5's architecture emerged during a conversation, although it appears the information might be speculative and based on extrapolations from other projects.
In-Depth BNF Explanation
- A user provided a comprehensive explanation of Backus-Naur Form (BNF) and how it impacts layer interactions within computer systems and the potential for memetic encoding in LLMs.
OpenInterpreter Community Discussions
Lively Debate Over Learning Preferences:
- Members shared diverse opinions on learning methods, with some finding YouTube challenging due to distractions and privacy concerns.
Interest in Local LLMs with Open Interpreter:
- Users are interested in integrating local LLMs with Open Interpreter to avoid external API costs and dependency on services like ClosedAI.
Diverse Opinions on Open Interpreter Documentation:
- Community calls for diverse documentation methods for Open Interpreter, suggesting a Wiki-style format with optional embedded videos.
Community Interest in Project Extensions:
- Users are actively seeking additional tools, platforms, and models to integrate with Open Interpreter for various applications.
Open Interpreter Community Growth and Feedback:
- The community is enthusiastic about the project's potential, focusing on enhancing usability and accessibility for diverse user needs.
Immediate Storage in RAM Request
The discussion in this section highlights the desire for immediate storage in RAM instead of creating a separate iterable dataset. Members expressed various requests and challenges, such as seeking help with specific HuggingFace models, exploring the benefits of converting models to Rust, and discussing the GPU support in the Candle library. Additionally, there are mentions of enhancing knowledge integration with LlamaIndex, new Python libraries like loadimg, and ongoing developments with LlamaTokenizer and Gradio for image processing. These discussions reflect the community's engagement in refining AI models and tools for better performance and efficiency.
LM Studio Discussions
- Quality Leap in Model Versions: Noticed improvements in IMATRIX Q5 and Q6 models surpassing regular counterparts, with some cases showing IMAT Q6 outperforming "reg" Q8.
- Longer Context Models Hunt: Search for models with 32K context length for RAG adjacent interactions, referencing Mistral 7b 0.2.
- Clarifications on Mistral Model: Discussed Mistral 0.2 model's 32K context length, correcting misconceptions of an 8K limit.
- Workaround for Screenshots: Shared Parsec to phone workaround for capturing screenshots without using the PC.
- RPG and Essay Writing Models: Inquiry about models for tabletop RPGs and essay writing, recommending Goliath 120b despite an 8K context limit.
- GPU Upgrades and Hardware Discussion: Conversations on upgrading GPUs for LLMs and gaming, preparation for new models like Llama 3 and Qwen 2, CUDA versions, and cost-performance comparisons.
- Troubleshooting CPU and RAM Usage: Help provided for high CPU and RAM usage issue, with advice on GPU load during model inference.
- Beta Releases Discussions: Topics on token limit issues, maintaining conversations, JSON output errors, model-specific JSON issues.
- Troubles with Moondream2 and Linux Releases: Members reporting compatibility problems with llava vision models and Moondream2, skipping Linux release version 0.2.16.
- TightVNC and LM Studio Channels: Mention of TightVNC as VNC-compatible free remote desktop software, followed by channel discussions on AI model feedback, hardware, beta releases, etc.
Investigating the Limits of N-Gram Models
There's an interest in understanding language models beyond n-gram statistics, with a proposal to examine transformers trained solely on n-gram distributions and to compare these mechanisms with full-scale language models.
LangChain AI Tutorials
- Tutorial en Español Sobre Chatbots: A member shared their work on AI Chatbot tutorials in Spanish, available on YouTube. The video could be useful for Spanish speakers interested in learning about chatbots and AI.
AI and Sales Agents, Voice Chat with Deepgram & Mistral AI, and CUDA Discussions
- AI as Sales Agents Video Guide: An AI sales agent was presented in a video guide on YouTube. The video explores how AI employees can outperform human employees.
- Voice Chat with Deepgram & Mistral AI: A tutorial video demonstrates voice chat using Deepgram and Mistral AI, with a Python notebook link on GitHub for integrating voice recognition with language models.
- CUDA Discussions: Discussions on topics related to CUDA, including Rapids and pandas for IO-bound operations, Flash Attention for Triton, collaborative kernel development, performance kernels, and more.
Using Prompt Formats for Multilingual Fine-Tuning
A user discussed the potential impact of using English prompt formats for fine-tuning on the quality of German outputs. They suggested using the target language's format and compared ChatML and Alpaca formats in English with proposed German equivalents. Another exchange focused on finding the German translation of the word 'prompt,' offering options like 'Anweisung,' 'Aufforderung,' and 'Abfrage.'
FAQ
Q: What are some key topics discussed in Discord communities related to AI?
A: Discussions in Discord communities cover topics like SD3 release impacts, advancements in AI-assisted video creation, face swapping algorithms like Reactor, open-source AI debate, hardware considerations for upscaling, performance comparisons between models, challenges in fine-tuning AI, ethical implications of developing ASI, integration issues with GPT Store, and the importance of precise prompts for LLMs.
Q: What technical challenges were addressed in Discord communities related to AI?
A: Technical challenges addressed in Discord communities related to AI include resolving 403 errors when accessing Anthropic models via OpenRouter, integrating models like GPT-4 and Claude-3 in coding tasks, addressing issues with model weight storage strategies, model interactions, and compatibility. Additionally, there were discussions on using Rapids and pandas for IO-bound operations, flash attention for Triton, custom quant kernels for AdamW8bit, and resolving technical hiccups in Windows bindings for PyTorch.
Q: What are some tools and models discussed in Discord communities related to AI?
A: Discord communities discussed tools and models like Opus, sillytavern for chat completion, Mistral model integration, Flash Attention for Triton, API synergy opportunities, performance kernels, Thunder tutorial, LLMs with Open Interpreter, Candle library GPU support, LlamaTokenizer, Gradio for image processing, IMATRIX Q5 and Q6 models, Mistral 7b 0.2 model, RAG models with long context lengths, and GPU upgrades for LLMs and gaming.
Q: What are some community interests and project discussions in Discord communities related to AI?
A: Community interests in Discord communities related to AI include enhancing kernels for performance, adding a Bulletin Board System (BBS) to a world simulator, discussing compute efficiency in LLMs, speculation on GPT-5 architecture, in-depth explanations of Backus-Naur Form (BNF), debates on learning preferences, interest in local LLMs with Open Interpreter, diverse opinions on Open Interpreter documentation, and seeking project extensions for Open Interpreter.
Q: What language-related discussions took place in Discord communities related to AI?
A: Language-related discussions in Discord communities related to AI included comparing prompt formats for fine-tuning models in different languages, finding translations for technical terms like 'prompt,' exploring language models beyond n-gram statistics, and creating tutorials in different languages like Spanish for chatbots.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!